Many times I’ve seen repetitive and obsessive validation of input parameters.
It may be a consequence of confusion in what “defensive programming” paradigm really is.
I will give a simple example – Let’s say we have a following code snippet:
public class HashWriter : IHashWriter
{
public bool SaveHashItem(int duration, string hashId, string itemKey, T item)
{
var retVal = true;
if (duration == 0)
{
throw new Exception("Duration must greater than 0!");
}
if (string.IsNullOrWhiteSpace(hashId))
{
throw new Exception("hashId must be specified!");
}
if (string.IsNullOrWhiteSpace(itemKey))
{
throw new Exception("itemKey must be specified!");
}
if (item.Equals(default(T)))
{
throw new Exception("item must have a non-default value");
}
retVal = RedisClientProvider.GetClient().SetEntryInHash(hashId, itemKey, item, duration);
if (!retVal)
{
throw new Exception("Failed to save item in Redis hash!");
}
return retVal;
}
}
So, this made me think – is this a good practice or upper code snippet is too “defensive”?
I think it’s a bad practice – if you keep doing this in each and every method you write.
Now, if I am “careless”, I will re-write this code like this:
public class HashWriter : IHashWriter
{
public bool SaveHashItem(int duration, string hashId, string itemKey, T item)
{
return RedisClientProvider.GetClient().SetEntryInHash(hashId, itemKey, item, duration);
}
}
But, what if we can have a flexible, middle solution? What if we can “automate” this repetitive code somehow? What if I can put assertive statements, just like in unit tests, but directly in the code, and rule them out, if needed? Even better, I don’t wish to have them in the code itself, but somewhere aside and I can configure if they run or not? I found solution with Code Contracts. It is just the right tool I needed.
It’s a set of pre-conditional and post-conditional checkups, statements like Contracts.Requires(), and Contract.Ensures(). The Code Contracts tool makes it configurable, so you can switch them off – compiler will ignore them. Some of them like post-conditions require IL rewrite in order to enforce validation. Basically, after install from this link, you have a project properties tab called Code Contracts where you can setup the behavior.

The best part about them is having the validation statements “aside”, so you can keep your own code short and readable, while having input/output validations still enforced. For more information, please see how to use the following attributes (Please study the links before getting further with the post): ContractClassAttribute && ContractClassForAttribute. So, after small refactoring, I can end up with following set of code:
[ContractClass(typeof(HashWriterContracts))]
public interface IHashWriter
{
bool SaveHashItem(int duration, string hashId, string itemKey, T item);
}
//Contract class
[ContractClassFor(typeof(IHashWriter))]
public abstract class HashWriterContracts : IHashWriter
{
public bool SaveHashItem(int duration, string hashId, string itemKey, T item)
{
Contract.Requires(duration > 0, "Duration must greater than 0!");
Contract.Requires(!string.IsNullOrWhiteSpace(hashId), "hashId must be specified!");
Contract.Requires(!string.IsNullOrWhiteSpace(itemKey), "itemKey must be specified!");
Contract.Requires(!item.Equals(default(T)), "item must have a non-default value");
Contract.Ensures(Contract.Result() == true, "Failed to save item in Redis hash!");
return false;
}
}
//Implementation
public class HashWriter : IHashWriter
{
public bool SaveHashItem(int duration, string hashId, string itemKey, T item)
{
return RedisClientProvider.GetClient().SetEntryInHash(hashId, itemKey, item, duration);
}
}
I went further with my idea – I automated repeated code with a smart code generation, introducing Roslyn. It’s a .NET compiler – I use to generate an interface implementation of validated class with placeholders for contract checks. I have also made a VS 2015 Solution Explorer menu item, based on Visual Studio Extensibility SDK, for file and code generation. I added some extras also, like Contract Proxy class, based on Proxy Design Pattern. After install, right-clicking on any interface in Solution Explorer gives you ‘Create Code Contracts’ menu item, like below:
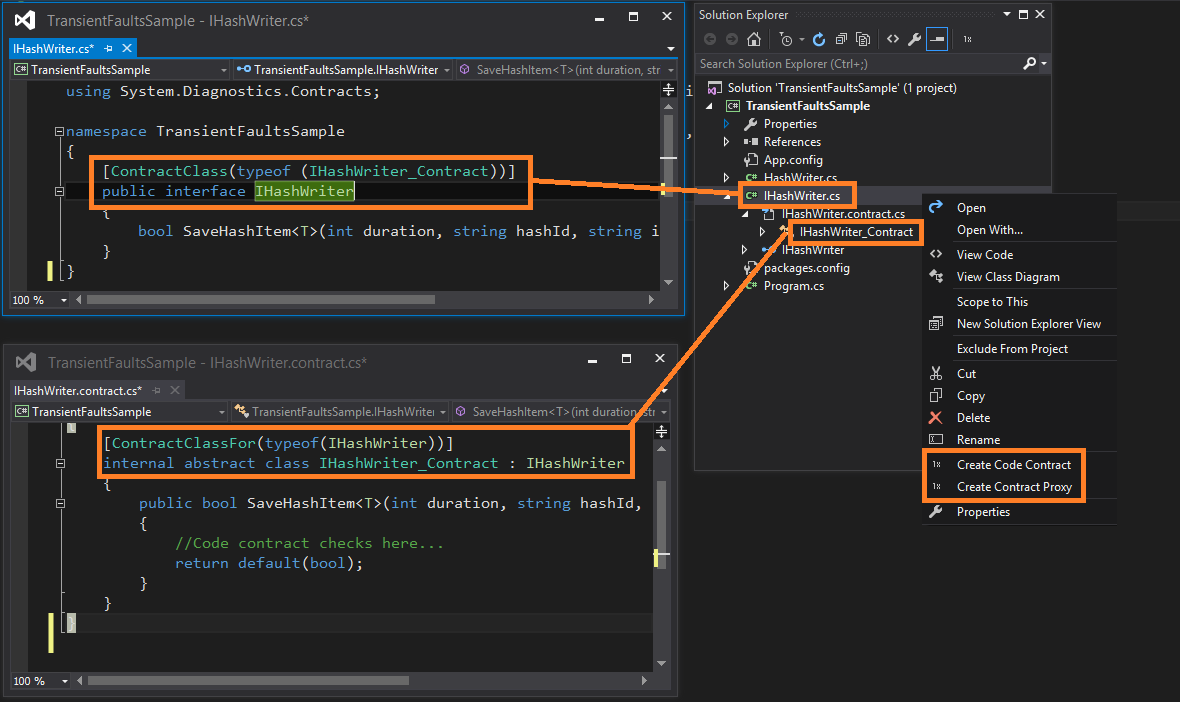
Tool is available for download here, it’s currently only for VS 2015 version, as Roslyn was not available before.
Lesson learned:
Classes, if they are clearly defined, have a simple Single Responsibility. Classes also have their context – places in code where they are used or re-used. If you are confused with any of these for your own class, then you might have a bad design. Not knowing what is your class responsibility or where they are used and how pushes you into the corner of thinking and re-validating every piece of code, even the simplest one. Few drawings on the board, class or sequence diagram should fix that easily, if you are stubborn and passionate enough.
Knowing your class’ responsibility also means you know well all contexts of class usage. That being said, it is important to have clear idea about how your class communicates with other classes and how methods within the class interact with each-other. When you are are clear about this, it makes you feel comfortable with assumptions you have for method’s input & output. That way you won’t allow contexts leading to wrong input & output and you will minimize internal validation code while concentrating on validating the class’ public surface layer ONLY. Exceptions deeper down the layers will clearly mean there is a use-case you have overseen.
So roughly speaking, ‘ideal’ class has single responsibility, between 1 and 3 public methods (preferably overloads) and few internal helper methods. All methods are ‘flat’ with simple control flow (low cyclomatic complexity with highest depth of 2 when it comes to nested calls in public methods). So in other words, if we visualize class as tree, methods as nodes and method calls as tree branches forming levels, we should always end up with tree with at most 3 levels. Why I am so precise? 🙂 Well, there is a simple reason: if we start abstracting class’ behavior in our mind, once we reach dept 3 we still can remember where we started while knowing where we are finished – so it’s easy to navigate and wrap our head around single class as a whole.